




Wer KI in seine E-Commerce-Prozesse einbinden will, lernt schnell: Die Qualität der Ausgabe hängt direkt von der Qualität der Eingabe ab. Produktbeschreibungen automatisch generieren, Attribute aus Bildern ableiten, Feedoptimierung per Regelwerk - all das funktioniert, wenn die Produktdaten strukturiert, korrekt und vollständig sind. Wenn nicht, skaliert die KI vor allem eines: das bestehende Chaos.
Dasselbe gilt für automatisierte Prozesse ohne KI. Ein Regelwerk, das Produkte kanalspezifisch ausspielt, funktioniert nur, wenn die zugrundeliegenden Daten den Kanal-Anforderungen entsprechen. Ein automatisierter Preis-Alert greift nur, wenn Einkaufs- und Verkaufspreise aktuell gepflegt sind.
Der erste Schritt ist deshalb nicht Automatisierung. Er ist Messbarkeit. Wer nicht weiß, in welchem Zustand seine Produktdaten sind, kann keine sinnvollen Automatisierungsregeln definieren und kein Dashboard aufbauen, das zeigt, ob sich die Qualität verbessert.
In diesem Beitrag geht es darum, welche fünf Dimensionen Produktdatenqualität bestimmen, wie du daraus ein messbares Scoring-Modell baust und warum die Anforderungen je nach Kanal unterschiedlich ausfallen. Warum schlechte Produktdaten geschäftlich teuer werden, haben wir in diesem Artikel beschrieben: Warum Datenqualität über deinen E-Commerce Erfolg entscheidet. Hier geht es ums Messen.
Produktdatenqualität misst sich in fünf Dimensionen
Die fünf Dimensionen, Vollständigkeit, Korrektheit, Konsistenz, Aktualität und Eindeutigkeit, sind als Begriffe bekannt. In der Praxis werden Produktdaten häufig nur hinsichtlich ihrer Vollständigkeit geprüft. Dabei bleibt außer Acht, dass ein Feld zwar befüllt sein kann und trotzdem gleichzeitig falsch. Es ist seit Monaten nicht aktualisiert oder in drei verschiedenen Schreibweisen im Sortiment vorhanden. Was diese Dimensionen genau bedeuten und wie leicht sich Fehler beheben lassen, erfährst du jetzt.
Dimension 1: Vollständigkeit - Pflicht- und Empfehlungsfelder trennen
Vollständigkeit klingt binär: Ein Feld ist entweder befüllt oder nicht. In der Praxis ist die entscheidende Frage nicht ob ein Feld befüllt ist, sondern welches Gewicht das Fehlen hat. So können Prioritäten gesetzt werden, anstatt alle Lücken gleichzeitig zu füllen.
Technische Pflichtfelder sind Felder, ohne die ein Produkt auf einem bestimmten Kanal nicht publiziert werden kann. Fehlt die EAN, lehnt Amazon das Listing ab. Fehlt der GTIN, erscheint das Produkt nicht im Google Merchant Center. Diese Felder sind nicht verhandelbar.
Empfehlungsfelder lösen keine Publikationssperre aus, beeinflussen aber Conversion und Sichtbarkeit messbar. Eine fehlende Zweitbeschreibung oder ein fehlendes Anwendungsbild sind kein technischer Fehler, aber sie kosten Umsatz. Gerade im eigenen Shop, wo kein Algorithmus die Publikation verhindert, entstehen hier unsichtbare Qualitätslücken.
Pflicht- und Empfehlungsfelder gibt es genauso bei Mediendaten. Ist ein Freisteller vorhanden? Sind Mindestanzahl und Mindestauflösung von Bildern erfüllt? Existiert ein Kontextbild, das das Produkt in Verwendung zeigt?
Genauso können Varianten betroffen sein: Das Hauptprodukt ist vollständig gepflegt, aber einzelne Größen- oder Farbvarianten hängen ohne eigene Bilder oder mit falschen Attributen im System.
Dazu können sich Pflicht- und Empfehlungsfelder pro Kanal variieren. Einige Kanäle definieren diese Anforderungen explizit, andere implizit über Ranking-Algorithmen.
Tipp: Definiere pro Kanal, welche Felder mandatorisch gefüllt sein müssen und welche optional sind. Ein bewährtes Prinzip für die Prüflogik: Fehlende Pflichtfelder werden als Fehler klassifiziert und blockieren die Publikation. Fehlende optionale Felder erzeugen eine Warnung. Das Produkt kann publiziert werden, aber das Optimierungspotenzial bleibt sichtbar.
Dimension 2: Korrektheit - Formatfehler automatisieren, inhaltliche Abweichungen redaktionell absichern
Korrektheit bedeutet, dass Feldinhalte mit der Realität übereinstimmen und formal valide sind. Das klingt einfach, kennt aber mindestens vier verschiedene Fehlertypen und nicht alle lassen sich automatisch erkennen.
Formatfehler entstehen meist beim Import aus Lieferantendaten. Einheiten werden inkonsistent geschrieben: "2,5 kg" in einem Datensatz, "2500 g" in einem anderen. Dasselbe Produkt, zwei verschiedene Darstellungen. HTML-Entities landen als Rohtext im Titel (& statt &). Diese Fehler sind regelbasiert und vollständig automatisierbar.
Validierungsfehler sind eindeutig prüfbar: Die EAN-Prüfziffer stimmt nicht. Der GTIN hat das falsche Format. Die Bildauflösung liegt unter dem Kanal-Minimum. Kein Ermessensspielraum, kein redaktionelles Urteil nötig.
Sprachliche Fehler umfassen Rechtschreibfehler, falsche Sprache im Feld (englischer Text in einem deutschen Pflichtfeld), uneinheitliche Großschreibung in Attributwerten. Teils automatisierbar über Wortlisten und Spellcheck-Regeln, teils redaktionell zu prüfen.
Inhaltliche Fehler sind die gefährlichste Klasse und die einzige, die sich nicht automatisieren lässt. Die Materialangabe stimmt nicht mehr, weil der Lieferant die Rezeptur geändert hat. Die Maßangabe weicht von der tatsächlichen Produktgröße ab. Das Feld ist befüllt, alle automatisierten Checks sind grün, aber der Inhalt entspricht nicht mehr dem Produkt.
Praxis-Tipp: Automatisiere Formatfehler und Validierungsfehler vollständig. Für inhaltliche Fehler braucht es einen Freigabeprozess bei Lieferantenänderungen: Wer Produktdaten liefert, muss Änderungen an Pflichtfeldern explizit markieren. Ohne diese Regel bleibt die inhaltliche Korrektheit dauerhaft ein blinder Fleck.
Dimension 3: Konsistenz - Einheitliche Darstellung über Attribute, Varianten und Kanäle hinweg
Konsistenz beschreibt, ob dieselbe Information überall gleich dargestellt wird, innerhalb eines Produkts, über Varianten hinweg und kanalübergreifend. Die Fehlerquelle ist fast immer dieselbe: unkontrollierter Datenzufluss aus mehreren Quellen ohne Normalisierungsregel.
Attributwert-Konsistenz ist das häufigste Problem. Wie viele verschiedene Schreibweisen existieren für "Schwarz" im Sortiment? "schwarz", "Schwarz", "Black", "#000000" und "Anthrazit-Schwarz" können im System für dieselbe Farbe stehen, wenn verschiedene Lieferanten verschiedene Werte liefern. Die Folge: Filternavigation funktioniert nicht zuverlässig, Cross-Selling-Regeln greifen nicht, und Suchalgorithmen gewichten Produkte mit inkonsistenten Attributen anders.
Varianten-Konsistenz betrifft Basisattribute wie Marke, Hersteller oder Herkunftsland, die über alle Varianten eines Produkts identisch sein sollten. Wenn dieselbe Jacke in Größe S unter "Marke: Muster GmbH" und in Größe XL unter "Marke: Muster" läuft, entstehen im PIM logisch zwei verschiedene Produkte – mit allen Konsequenzen für Auswertungen und Algorithmen.
Kanalübergreifende Konsistenz ist die dritte Ebene. Amazon-Titel und Shop-Titel desselben Produkts widersprechen sich inhaltlich. Kein System löst das aus – aber es beschädigt die Markenwahrnehmung und kann bei Marktplätzen Vertrauen kosten.
Dimension 4: Aktualität - Unterschiedliche Felder brauchen unterschiedliche Verfallsintervalle
Aktualität bedeutet, dass Feldinhalte dem aktuellen Zustand der Realität entsprechen. Die entscheidende Nuance: Verschiedene Felder haben verschiedene Verfallsintervalle.
Preis und Verfügbarkeit können sich täglich oder stündlich ändern. Ein veralteter Preis im Google Shopping Feed führt zur Ablehnung im Merchant Center. Ein falscher Lagerbestand führt zu Überverkäufen.
Technische Spezifikationen verfallen, wenn ein Lieferant das Produkt reformuliert oder umbaut - ohne Meldung. Das Feld ist befüllt, der Score ist grün, aber der Inhalt entspricht nicht mehr dem tatsächlichen Produkt. Das ist der häufigste inhaltliche Korrektheitsfehler, der sich als Aktualitätsproblem tarnt.
Bilder veralten, wenn eine Verpackung geändert wird. Das Foto zeigt die alte Verpackung, das Produkt auf der Palette sieht anders aus. Dieser Fehler ist im System vollständig unsichtbar bis ein Kunde reklamiert oder die Retourenquote steigt.
URLs in Produkttexten sind eine eigene Fehlerquelle. Links auf externe Seiten, Zertifikate oder weiterführende Dokumente führen ins Leere, wenn Zielseiten abgebaut werden. Ein toter Link in einer Produktbeschreibung ist ein Aktualitätsproblem, kein Vollständigkeitsproblem und er lässt sich vollständig automatisiert erkennen.
Praxis-Tipp: Definiere Prüfintervalle nach Feldkategorie: Preis und Verfügbarkeit täglich, technische Specs bei jedem Lieferanten-Update, Bilder und URLs quartalsweise.
Dimension 5: Eindeutigkeit - Keine Dubletten bei SKUs, Varianten und Kategorien
Eindeutigkeit bedeutet, dass jedes Produkt genau einmal im System existiert. In gewachsenen Sortimenten mit mehreren Datenquellen ist das keine Selbstverständlichkeit.
Doppelte SKUs durch parallele Importe entstehen, wenn zwei Lieferanten dasselbe Produkt liefern. Beim Import entstehen zwei separate Datensätze mit unterschiedlichen Artikelnummern, unterschiedlichen Preisen und leicht abweichenden Beschreibungen. Der Shop zeigt dasselbe Produkt zweimal, aber mit verschiedenen Preisen.
Varianten als Einzelartikel entstehen, wenn eine Farbvariante fälschlich als eigenständiger Artikel angelegt wurde statt in der Eltern-Kind-Struktur. Das führt zu falschen Bestandsanzeigen und zerstört die Variantennavigation.
Kategoriedubletten entstehen, wenn dasselbe Produkt in mehrere Kategorien eingehängt ist, die nicht als Mehrfachzuordnung gedacht sind. Das verzerrt Auswertungen und macht Preisregeln unzuverlässig.
Von der Dimension zur Metrik - die entscheidende Übersetzungsarbeit
Die fünf Dimensionen beschreiben, was gemessen werden soll. Aber noch nicht, wie. Der Schritt dazwischen ist konkreter als er klingt: Für jede Dimension brauchst du Prüfregeln, die eindeutig genug sind, um automatisiert ausgeführt zu werden. Was zählt als Pflichtfeld für diesen Kanal? Welche Zeichenlänge ist erlaubt? Welche Attributwerte sind normiert?
Wer das einmal definiert hat, kann einen Score berechnen und entscheiden, wie stark einzelne Dimensionen ins Gesamtergebnis einfließen. Eine Gewichtung ist keine technische Frage, sondern eine strategische: Wer hauptsächlich auf Amazon verkauft, gewichtet Vollständigkeit und Korrektheit höher. Im eigenen Shop zählen dafür ausführliche Produktbeschreibungen und Zusatzfelder. Der Aufwand liegt in der Einrichtung, danach läuft es automatisiert.
Ein Scoring-Modell bauen
Jedes Produkt bekommt pro Dimension einen Punktwert zwischen 0 und 100. Die gewichtete Summe ergibt den Gesamtscore. Der Score lässt sich auf Produktebene, Kategorieebene, Lieferantenebene und kanalspezifisch auswerten.
Die Gewichtung hängt davon ab, welche Dimension auf dem primären Absatzkanal die größten Konsequenzen hat.
Ein Beispiel zur Berechnung des Gesamtscores
Ein Produkt hat für den Amazon-Kanal 14 relevante Felder: 10 Pflichtfelder und 4 Empfehlungsfelder. 9 Pflichtfelder sind korrekt befüllt, 1 fehlt. 3 Empfehlungsfelder sind befüllt, 1 fehlt.
| Messung | Berechnung | Ergebnis |
|---|---|---|
| Vollständigkeit Pflichtfelder | 9 ÷ 10 × 100 | 90 % |
| Vollständigkeit Empfehlungsfelder | 3 ÷ 4 × 100 | 75 % |
| Gewichteter Vollständigkeitsscore (Pflicht 70 %, Empfehlung 30 %) | (90 × 0,7) + (75 × 0,3) | 85,5 % |
| Korrektheit (2 Fehler in 9 befüllten Feldern) | (9 − 2) ÷ 9 × 100 | 78 % |
| Gesamtscore (Vollständigkeit + Korrektheit je 50 %) | (85,5 × 0,5) + (78 × 0,5) | 81,8 % |
Für die Auswertung empfiehlt sich ein Ampelsystem:
- Unter 60 %: rote Ampel – Produkt nicht publikationsreif
- 60–80 %: gelbe Ampel – publizierbar, mit bekannten Einschränkungen
- Über 80 %: grüne Ampel – kanalkonform
Formeln zur Berechnung der Dimensionen
Diese Formeln lassen sich direkt in eine Tabellenkalkulation übertragen:
| Dimension | Formel | Automatisierungsgrad |
|---|---|---|
| Vollständigkeit | befüllte Pflichtfelder ÷ Gesamtzahl Pflichtfelder × 100 | Vollständig automatisierbar |
| Korrektheit (Format) | fehlerfreie Felder ÷ befüllte Felder × 100(nicht durch Gesamtfelder - sonst verzerren leere Felder den Wert) | Vollständig automatisierbar |
| Korrektheit (Inhalt) | Stichprobenquote aus manuellem Audit | Nicht automatisierbar |
| Konsistenz | normierte Attributwerte ÷ Gesamtzahl Attributwerte pro Attribut × 100 | Vollständig automatisierbar |
| Aktualität | Produkte mit Aktualisierung im Prüfintervall ÷ Gesamtzahl Produkte × 100 | Teilweise automatisierbar |
| Eindeutigkeit | (Gesamtzahl Produkte − Anzahl Dubletten) ÷ Gesamtzahl Produkte × 100 | Vollständig automatisierbar |
| Gesamt Score | Summe (Dimensionsscore × Gewichtung) | Vollständig automatisierbar |
Tipp: Werte den Score nicht nur auf Produktebene aus, sondern aggregiert nach Lieferant. Wenn eine Lieferantenquelle systematisch Formatfehler produziert, ist das ein Prozess-Problem, kein Datenproblem und es löst sich nicht durch Einzelkorrekturen.
Kanalspezifische Anforderungen – warum ein Score nicht reicht
Derselbe Datensatz kann im eigenen Shop grüne Ampel haben und auf einem Marktplatz trotzdem abgelehnt werden. Nicht weil die Daten schlechter wurden, sondern weil jeder Kanal eigene Pflichtfelder, Formatregeln und Qualitätsschwellen definiert. Ein kanalunabhängiger Gesamtscore ist deshalb nur der Ausgangspunkt, kein Urteil.
Das Grundprinzip lässt sich auf drei Kanal-Typen herunterbrechen, die sich in ihrer Fehlerlogik grundlegend unterscheiden:
Marktplätze mit automatisierter Prüfung
Amazon, OTTO, Kaufland und vergleichbare Marktplätze prüfen Produktdaten vollständig maschinell. Fehlen Pflichtfelder oder werden Formatvorgaben verletzt, wird das Listing automatisch abgelehnt oder gesperrt, ohne manuelle Prüfoption und oft ohne erklärendes Fehlerbild. Die Konsequenz ist nicht sinkende Conversion, sondern komplette Nicht-Sichtbarkeit.
Das Besondere an dieser Kanal-Klasse: Die Anforderungen ändern sich regelmäßig und variieren je nach Produktkategorie. Was für Elektronik gilt, gilt nicht für Lebensmittel. Was heute ausreicht, kann nach dem nächsten Plattform-Update ein Fehler sein. Die verbindliche Quelle sind deshalb immer die aktuellen Seller-Dokumentationen der jeweiligen Plattform, nicht statische Checklisten.
Für diesen Kanal-Typ gilt: Vollständigkeit und Korrektheit haben das höchste Gewicht im Score-Profil. Und Readiness-Checks müssen bei jeder Datenänderung automatisch neu ausgeführt werden, nicht nur einmalig beim Anlegen.
Feed-basierte Kanäle
Google Shopping, idealo und ähnliche Preisvergleichskanäle beziehen Produktdaten über Feeds, die regelmäßig neu eingelesen werden. Fehler führen zur Ablehnung einzelner Produkte im Feed, nicht zur Sperrung des gesamten Kontos. Aber: Preisabweichungen zwischen Feed und Landingpage werden beispielsweise vom Googlebot aktiv gecrawlt und führen zur vorbeugenden Ablehnung der betroffenen Produkte.
Der entscheidende Qualitätsfaktor hier ist Aktualität. Preis, Verfügbarkeit und Bild-URL müssen den tatsächlichen Zustand des Shops zum Zeitpunkt des Crawlings korrekt abbilden. Ein veralteter Feed ist kein Vollständigkeitsproblem – er ist ein Aktualitätsproblem, das sich in Ablehnungsraten niederschlägt.
Eigener Shop
Hier gibt es keine technische Ablehnung. Die Konsequenz schlechter Daten ist nicht Sperrung, sondern entgangener Umsatz ohne jedes Fehlersignal. Das ist die tückischste Konstellation: Der Score ist grün, weil alle Pflichtfelder befüllt sind, aber der Kunde kauft nicht, weil die Beschreibung veraltet ist, Variantenbilder fehlen oder die Filternavigation wegen inkonsistenter Attributwerte nicht funktioniert.
Tipp: Ergänze den technischen Score für den eigenen Shop um einen Richness-Check: Mindest-Wortanzahl in der Beschreibung, Mindestanzahl Bilder, Vorhandensein von Cross-Selling-Attributen. Diese Felder erzwingen keine Sperrung, aber ihr Fehlen lässt sich messen und priorisieren.
Das Prinzip hinter allen drei Kanal-Typen ist dasselbe: Definiere pro Kanal ein eigenes Score-Profil mit kanalspezifischen Gewichtungen. Nur so siehst du auf einen Blick, welches Produkt wo ein Problem hat, statt einen Durchschnittswert zu verwalten, der nichts verrät.
Was sich automatisieren lässt – und was nicht
Für ein kleines, überschaubares Sortiment lässt sich ein Scoring-Modell manuell oder in einer Tabellenkalkulation abbilden. Sobald Produktanzahl, Variantentiefe oder Attributkomplexität wachsen, wird das schnell unpraktikabel. Ohne Automatisierung wird in der Praxis gar nicht mehr geprüft.
Folgende Checks lassen sich vollständig automatisieren:
- Pflichtfeld-Vollständigkeit (befüllt / nicht befüllt)
- Textlängen nach Zeichen- und Wortanzahl
- Formatvalidierung: EAN-Prüfziffern, GTIN-Format, Einheitenschreibweise
- Bild-Checks: Auflösung, Dateigröße, Seitenverhältnis, Dateiformat
- URL-Erreichbarkeit: tote Links in Produkttexten per HTTP-Statusprüfung
- Dubletten-Erkennung via EAN oder GTIN
- Wort-Checks: verbotene Begriffe, abmahngefährdete Wörter, Konkurrenten-Namen
Nicht vollständig automatisierbar sind inhaltliche Korrektheit (stimmt die Materialangabe noch?), Bild-Aktualität (zeigt das Foto noch die aktuelle Verpackung?) sowie Relevanz und Verständlichkeit von Beschreibungen. Diese Felder brauchen redaktionelle Stichproben, keine vollständige manuelle Prüfung, aber eine systematische Stichprobenstrategie.
Praxis-Tipp: Automatisiere zuerst die Checks mit eindeutigen Regeln. Sie decken den größten Teil aller strukturellen Fehlerquellen ab. Danach lässt sich die inhaltliche Qualität mit gezielten Stichproben angehen, statt das gesamte Sortiment manuell durchzuarbeiten.
Wie Hublify Produktdatenqualität misst
Hublify überprüft deine Datenqualität auf Basis von konfigurierbaren Check-Sets, Gruppen von Einzelchecks, die jeweils einen Datenbereich abdecken. Diese drei Sets übernehmen die verschiedenen Dimensionen:
Completeness prüft, ob alle notwendigen Felder befüllt sind. Consistency überprüft formale Kriterien zu Korrektheit, Einheitlichkeit, Redundanzfreiheit und Aktualität - und damit den größten Teil der automatisierbaren Checks. Richness analysiert inhaltliche Tiefe, Verständlichkeit und Relevanz. Alle drei Sets lassen sich pro Datentyp und Kanal separat konfigurieren.
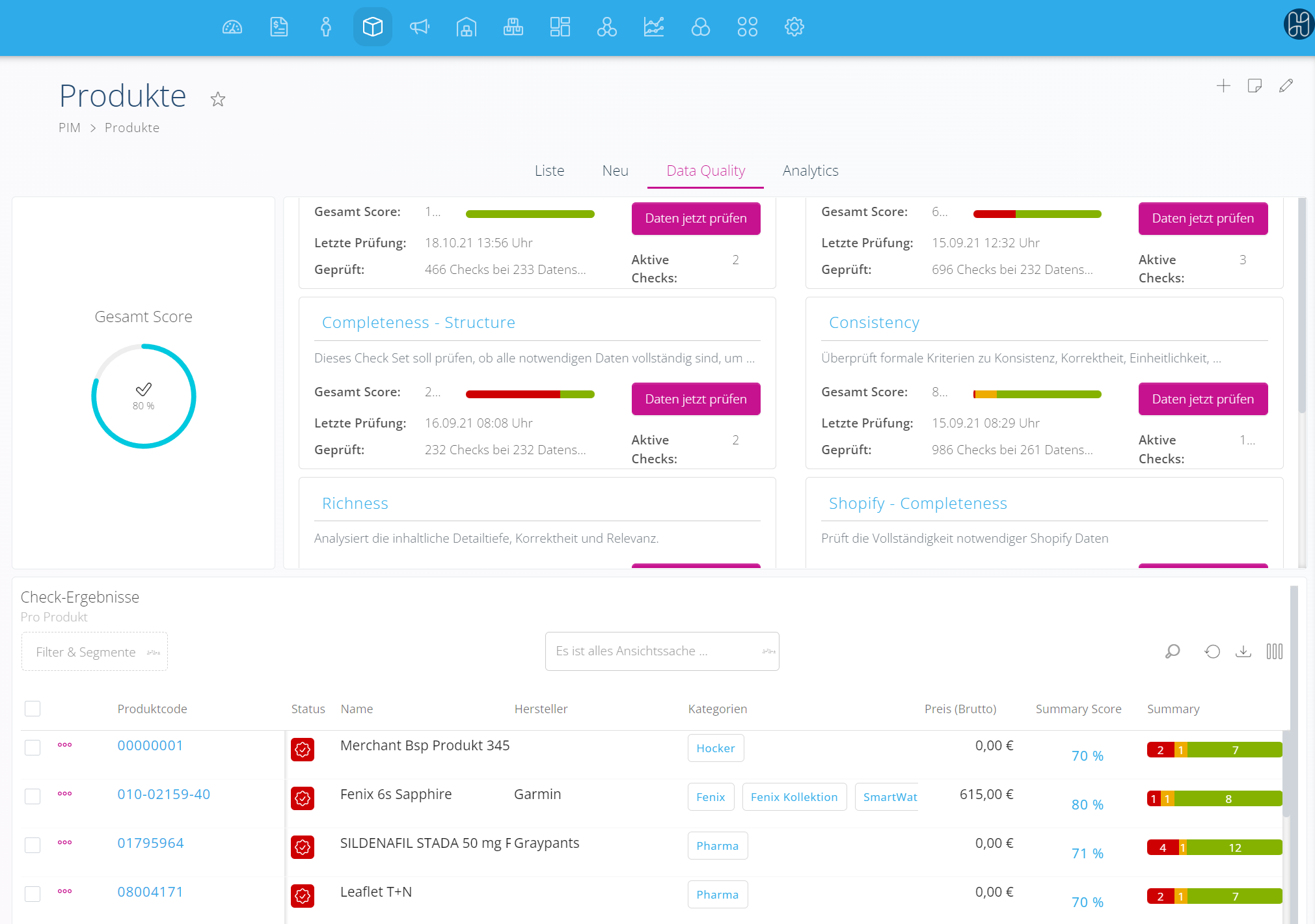
Was das in der Praxis bedeutet, zeigt die Produktliste im PIM: Jedes Produkt hat einen Summary Score, der auf einem Blick zeigt, wo Handlungsbedarf besteht. Auf Ebene des Sortiments gibt ein Gesamt Score den aggregierten Zustand wieder. Wer tiefer einsteigen will, sieht per Klick auf die Summary die Aufschlüsselung nach Check Set – und darunter die konkreten Einzelfehler auf Feldebene: "brand kann nicht leer sein" als Error, ein optionales Feld ohne Inhalt als Warning. Die Unterscheidung zwischen Error und Warning ist dabei keine kosmetische – sie bestimmt direkt, ob ein Produkt für die Publikation gesperrt ist oder nur Optimierungspotenzial hat.
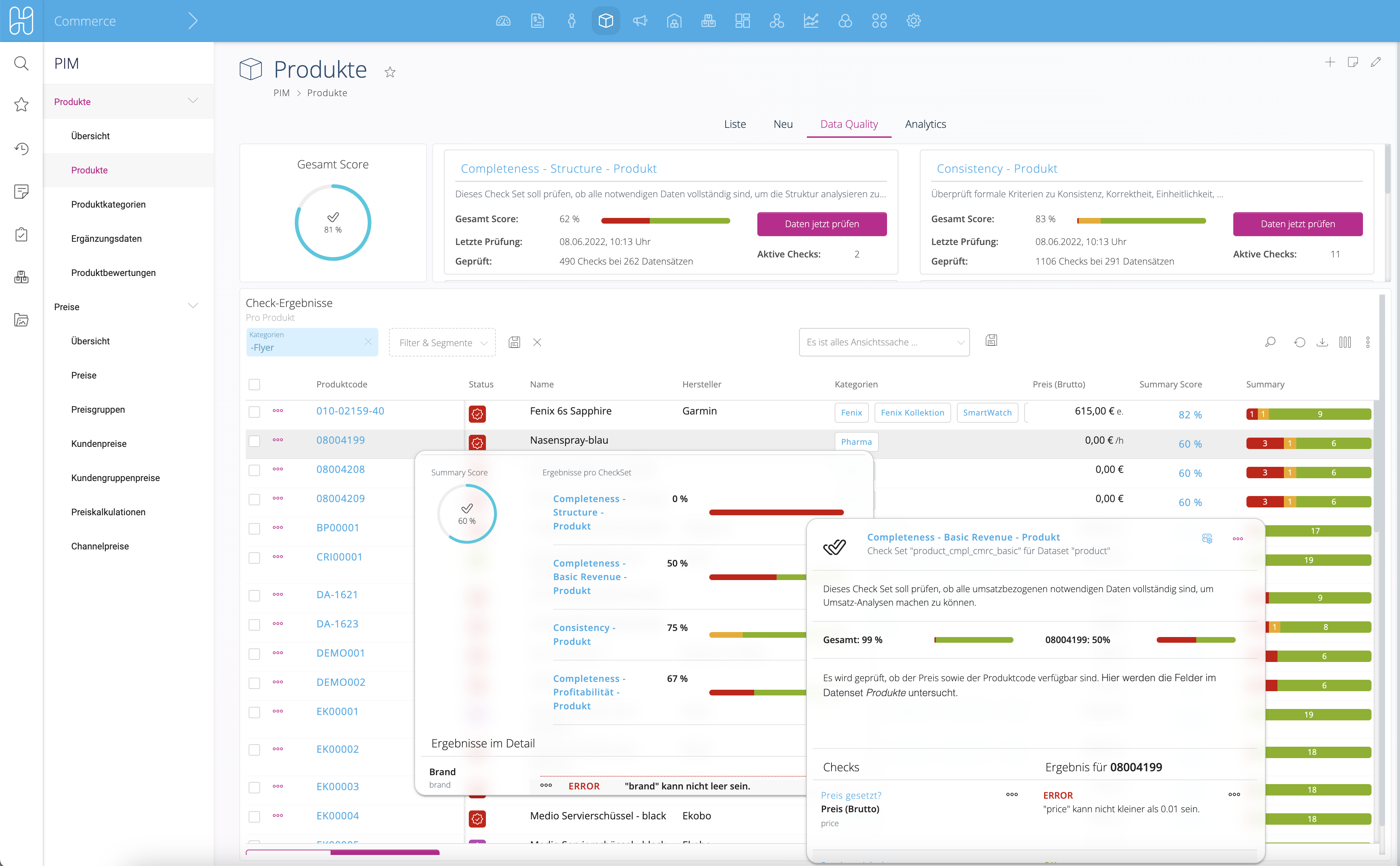
Die Check-Typen decken alle regelbasierten Prüfungen ab: Pflichtfeld-Vollständigkeit, Textlängen nach Zeichen- und Wortanzahl, Zahlen- und Datumsvalidierung, URL-Erreichbarkeit per HTTP-Statusprüfung sowie Bild-Checks für Auflösung, Dateigröße und Format. Über die Funktion Check Wörter lässt sich zusätzlich ein firmeninternes Dictionary pflegen: verbotene Begriffe, abmahngefährdete Wörter oder Konkurrenten-Namen - mit automatischem Synonym-Vorschlag für einheitliche Schreibweisen im gesamten Sortiment.
Check Sets lassen sich bei jeder Datenänderung automatisch auslösen oder zeitgesteuert planen. Der Preis-Alert greift, sobald der Verkaufspreis unter den Einkaufspreis fällt oder eine definierte Marge unterschritten wird.
Falko Borkhart von der Jungherz GmbH beschreibt das Ergebnis in der Praxis: Rund 80.000 Produkte aus verschiedenen Quellen wurden im Rahmen einer Migartion in zwei Tagen aggregiert, geprüft und publiziert. Mehr zu Hublify Product Data Quality findest du auf der PIM-Produktseite.
Produktdatenqualität messen ist die Voraussetzung, verbessern der nächste Schritt
Wer jetzt weiß, wo die roten Ampeln leuchten, fragt sich als nächstes: Wie baut man einen Prozess auf, der systematisch verbessert statt nur dokumentiert? Das beschreiben wir in diesem Artikel: Wege zur Verbesserung der Datenqualität im eCommerce.
Lass uns gerne darüber sprechen, wie das für dein Sortiment aussehen könnte: Lass dir Hublify zeigen!
FAQ: Häufige Fragen zur Messung von Produktdatenqualität
Wie oft sollte ich Produktdatenqualität prüfen?
Das hängt vom Feldtyp ab. Preis und Verfügbarkeit sollten kontinuierlich oder täglich geprüft werden, diese Felder veralten schnell und haben direkte Auswirkungen auf Marktplatz-Feeds und Überverkäufe. Technische Spezifikationen und Beschreibungen reichen mit einer monatlichen Prüfung oder einem Check bei jeder Lieferantenänderung. Bilder und URLs empfehlen sich quartalsweise. Ein automatisiertes System führt diese Checks bei jeder Datenänderung aus, manuelle Intervalle sind nur ein Fallback, wenn keine Automatisierung vorhanden ist.
Was ist ein guter Data Quality Score?
Es gibt keinen universellen Schwellenwert, denn der hängt vom Kanal und vom Gewichtungsmodell ab. Als Orientierung hat sich folgendes bewährt: Unter 60 % ist ein Produkt nicht publikationsreif. Zwischen 60 und 85 % ist es publizierbar, hat aber bekannte Lücken. Über 85 % gilt als kanalkonform. Wichtiger als der absolute Wert ist die Entwicklung über Zeit: Ein Sortiment, das von 65 % auf 80 % verbessert wird, ist aussagekräftiger als ein statischer Score von 90 %, der nie geprüft wurde.
Ab wann lohnt sich ein automatisiertes Scoring?
Sobald manuelle Prüfung dazu führt, dass sie in der Praxis nicht mehr stattfindet. Das ist bei den meisten Sortimenten schnell erreicht – nicht unbedingt durch Produktanzahl, sondern durch Variantentiefe, Attributkomplexität oder die Anzahl der Datenquellen. Wer Produkte aus mehr als einer Quelle importiert oder mehr als zwei Kanäle bespielt, hat in der Regel mehr Fehlerquellen, als sich manuell überwachen lassen.
Muss ich alle fünf Dimensionen gleichzeitig einführen?
Nein. Sinnvoll ist, mit Vollständigkeit anzufangen, diese Dimension ist am einfachsten zu messen und deckt die häufigsten Fehlerquellen ab. Korrektheit und Eindeutigkeit lassen sich direkt ergänzen, weil sie ebenfalls regelbasiert prüfbar sind. Aktualität und Konsistenz erfordern mehr Konfigurationsaufwand, zahlen sich aber besonders bei wachsenden Sortimenten und mehreren Kanälen aus.
Der Schlüssel liegt darin, Qualität nicht als Gefühl, sondern als messbaren Score zu behandeln, pro Dimension, pro Kanal, automatisiert ausgewertet und in einem Dashboard sichtbar. Erst dann lassen sich Automatisierungsregeln definieren, die tatsächlich greifen. Und erst dann liefert KI Ausgaben, die besser sind als die Eingaben.

